
小白也看得懂的SEO基本原理,让你更了解百度背后的故事
本文并不是科普文,也不是什么技术探讨文。仅仅是为了那些和我一样,因为对“程序”、“代码”的望而却步,不敢或没有信心研究SEO的“小白”们,能快速简单有趣地了解搜索引擎背后的原理和逻辑,以便建立对互联网营销的基本认识。
感谢Zac的《SEO实战密码:60天网站流量提高20倍》

图:PEXELS
文:幺幺本文约2800字,阅读时间为4分钟。
作为营销人员,你会发现SEO离你很远也离你很近。工作中明明有个别同事专门做SEO,你却完全摸不懂他具体做一些什么?
我们好奇却从不去研究时,SEO其实离我们很远。
然而当我们开始把职业规划往上提的时候,当我们开始找工作的时候,发现很多公司对营销人员、运营人员的要求是“懂SEO/SEM”。
这个时候,SEO又离我们很近,近到你不得不去正视它。
基本定义:
SEO:是由英文SearchEngineOptimization缩写而来,中文意译为“搜索引擎优化”。
是指在了解搜索引擎自然排名机制的基础之上,对网站进行内部及外部的调整优化,改进网站在搜索引擎中关键词的自然排名,获得更多的展现量,吸引更多目标客户点击访问网站,从而达到互联网营销及品牌建设的目标。
有点复杂?其实你搞清楚3个基本概念就好了。

1、研究算法:百度这类网站不是凭感觉对搜索结果进行排序的,它有一套复杂的规则,以保证用户能搜到他想要的内容。
2、网站优化:研究清楚(或者大致清楚)百度这类搜索引擎的算法后,根据其喜欢或者讨厌的内容,调整我们自己的网站内容。包括关键词、内外链接、网站结构等等。
3、获得排名:这是SEO的目的,也是所有一切的起点。
所以我对SEO的理解就是,通过研究和利用搜索引擎的排名方法,将我们想要推广的网页排在前面。
由于篇幅的原因,我们今天仅探讨,搜索引擎是怎么展示给我们搜索结果的。
我们在百度的搜索框里面输入词,按下enter键就能出来这么多页的结果,而且似乎大部分都是我们想要的。
搜索引擎它是怎么做到的,是背后有小小的兵工厂在不断整理和输送我们想要的文件吗?或者是像汽车一样后面有整套的动力系统吗?
如果说程序、代码等,可能大家会觉得太抽象,无法想象它的样子。接下来我们用几个相对具象的事物举例,来说明搜索引擎背后的原理和逻辑。
一、像蜘蛛网一样“搜罗”信息(互联网就是是个蜘蛛网)
蜘蛛顺着蜘蛛网,从一条线爬到另一条线(从一个网页爬到另一个网页)。还顺便把爬到的数据丢进一个箱子存储起来。这就是搜索引擎的第一步“搜罗”。
那网页之间是怎么联系起来的呢?就是蜘蛛网的这条线与那条线之间有个节点一样,网页与网页之间也有链接,相当于蜘蛛网的节点,让蜘蛛从一个网跳转到另一个网。

互联网就像一个蜘蛛网
二、像图书馆一样“分析+整理”(箱子里都是原始数据,又多又杂怎么办?分门别类!)
前面我们说过,蜘蛛会把爬到的数据放在一个箱子里,但这些原始数据没法直接用,就像你去图书馆找一本书,结果图书管理员说书堆在房间里,自己去一个个翻。你觉得你找到自己想要的书的概率有多大?要花多长时间?
所以这个时候就要对原始数据进行预处理,也就是索引。就像图书馆将图书分门别类一样。这里就是搜索引擎的“分析和整理”。

蜘蛛爬取到的数据在没处理前,就跟没分门别类的图书馆一样
1、先把每个网页解析成文字:
搜索引擎的本质是基于文字的处理,而每个网页都是包含了无数关键词和非关键词的组合。
(1)提取文字:把每个网页看成一个文件夹,里面可能有文字、图片、视频。但搜索引擎会提取其中的文字。
(2)中文分词:把句子切成文字。
(3)把非关键词去掉。如“的”“地”“得”等助词、“啊”“哦”“呀”等感叹词、“从而”“以”却等副词或介词去掉。
另外还有消除噪声如导航栏、分类广告等对页面主题没有什么作用的去掉,以及去重后,最后将每个网页(也就是文件夹)变成一个个的关键词,如下图。
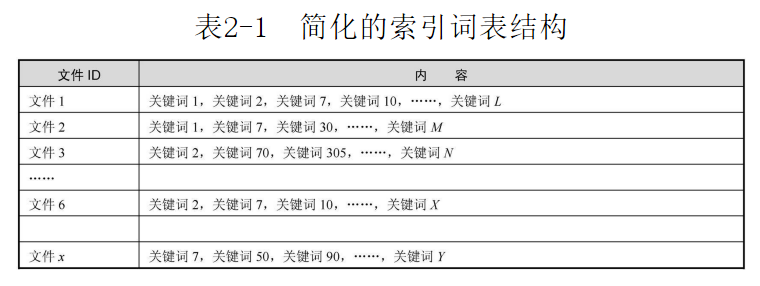
2、再给它进行更“人性化的组合”:
但是,解析到的正向索引还不能直接用于排名。为什么呢?如果用户搜索关键词2,程序就要扫描所有的文件来找出哪些文件有关键词2,耗时又耗力。怎么办呢?
用户是根据关键词来搜索的,那我们完全可以通过关键词进行索引排序呀。这就倒排索引:即根据关键词排列文件夹,具体如下图:
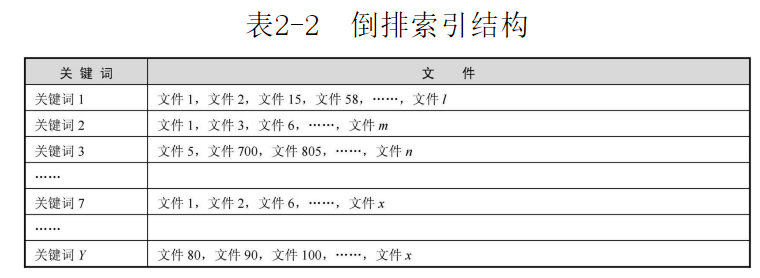
3、最后计算“相关性”和“可信性”:链接关系计算
现在我们再次回到搜索引擎的原理:按下enter键后,出来的网页是按照与你搜索词相关的顺序排序的(相关性),同时也要保证你搜索的是你想要的(可信度)。那么如何确定?
举个例子,马路上你碰到一个陌生人,你怎么确定你和他的关系,以及他的人品如何?如果他是你大姨夫的同学的邻居的同事,这就是通过“链接关系”确定相关性。而你对你大姨夫、大姨夫同学、大姨夫同学的邻居的人品和说辞来判断这个人的人品,这就是通过“PR值”确定可信度。
这里只是很简要的说明了链接关系计算的大致原理,真实的计算复杂度和维度是我们难以想象的。

确定链接关系,就像确定你与另一个人之间的关系一样
4、排名:一切准备就绪,网民可以开始搜索了
齿轮和齿轮才会合得起来,齿轮是没法与螺丝匹配的。
所以,既然程序把网页编程了关键词对应文件夹的组合,那么用户搜索时,也要提取关键词才能匹配相应的文件。
(1)提取关键词:这里也包括中文分词、把非关键词去掉、拼写错误矫正等等。
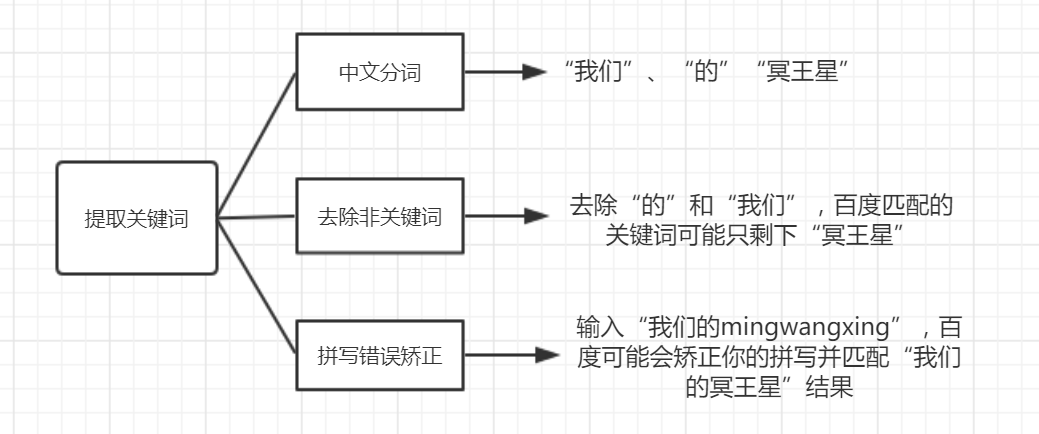
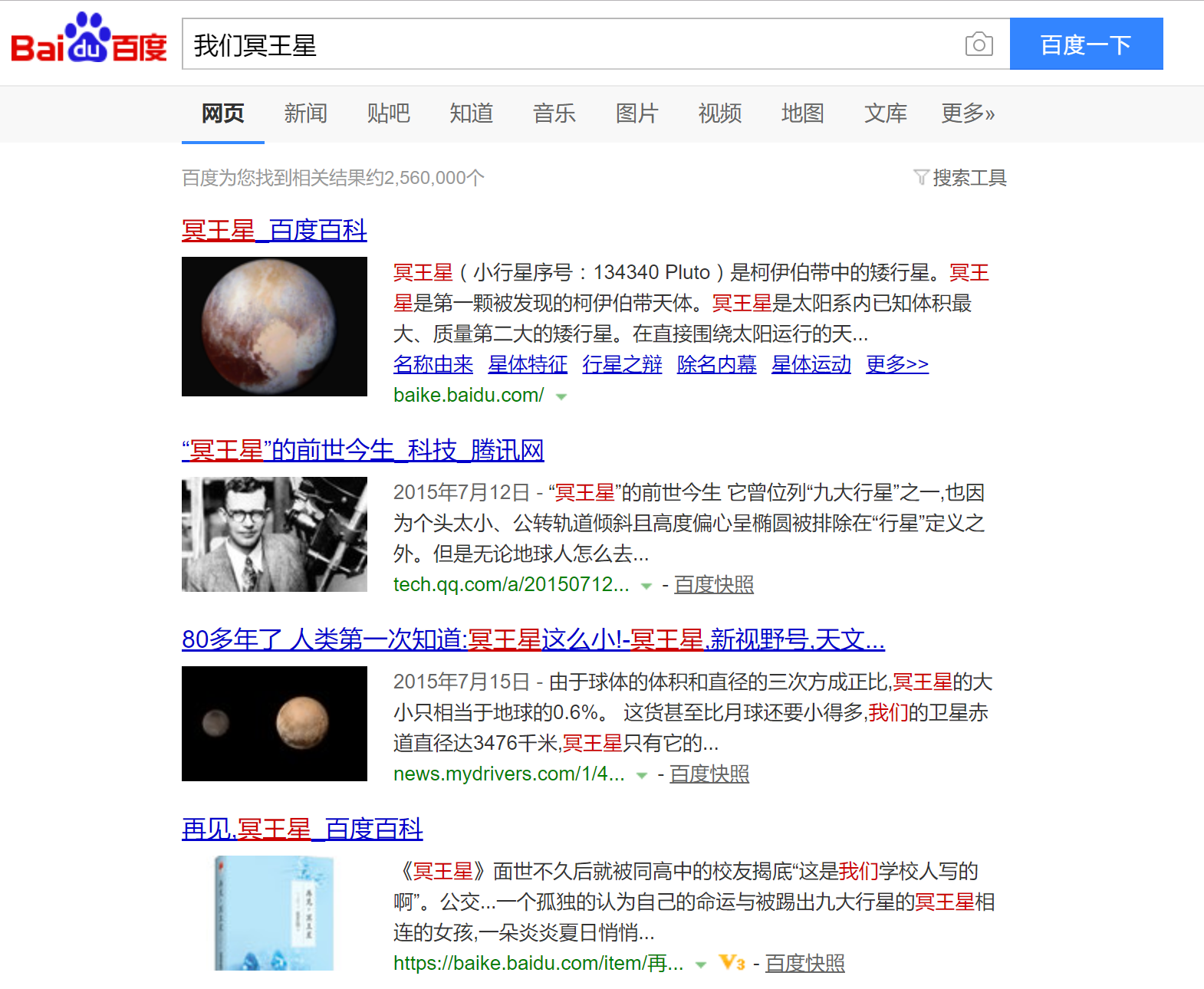
用户输入“我们的冥王星”,百度可能的提取结果
(2)文件匹配:提取出关键词后,就可以根据前面所说的倒排索引找出对应的“文件夹”,其实也就是网页。

关于“冥王星”,搜索引擎可能匹配出几千万个文件请点击此处输入图片描述
(3)初始子集选择:一般来讲,一个关键词对应的网页(文件夹)可能有上千万个,但用户可能只需要1000个。所以,搜索引擎会只选择一部分匹配的子集再进行后续的相关性计算以便排序。(至于怎么选取子集,文章里没有讲,可能属于算法的高级机密,一般人也不知道。)
(4)相关性计算:绝对情况下,以“冥王星”为例,如果一个网页上,“冥王星”这个次出现的频率越多、出现的位置越重要(如标题)、外部因为“冥王星”导入到这个网页的链接越多,则搜索引擎会觉得这个页面与“冥王星”越相关,越能排在前面。(其实搜索引擎的相关性排序非常复杂,这里方便大家理解,只能绝对化讲。)

通过“预处理”后的数据,如整理好的图书馆一样不仅井井有条,还方便查询
三、像“贴标签”一样做最后排名
贴标签可以让你快速了解一个人,或者是一个网页
最后,就是排名显示了。
通过前面的一步步,后台各种数据已经准备完成,现在只剩下给“图书馆的书贴标签”了。所以搜索引擎最后只用调用原始页面的标签标标签、说明标签、快照日期等显示再页面上。就形成了我们最终搜索结果。
通过上述一系列的计算,促成了我们一秒搜出相关网页的结果。是不是很神奇?
本文仅讲述了搜索引擎的原理,如果大家有兴趣,后续可能会整理SEO人员针对这些原理如何对网页进行优化的相关内容。如果想要更深入了解SEO,建议还是去看Zac的原书。
因为幺幺也是第一次接触SEO,如果文中有错漏,欢迎大家一起探讨进步。